*原创作者:VillanCh
0×00 介绍
0×01 要求
0×02 你能学到什么?
0×03 知识补充
0×04 最简单的开始
0×05 更优雅的解决方案
0×06 url合法性判断
0×07 总结与预告
0×00 介绍
爬虫技术是数据挖掘,测试技术的重要的组成部分,是搜索引擎技术的核心。
但是作为一项普通的技术,普通人同样可以用爬虫技术做很多很多的事情,比如:你想了解一下FreeBuf所有关于爬虫技术的文章,你就可以编写爬虫去对FreeBuf的文章进行搜索,解析。比如你想获得淘宝某类商品的价格,你可以编写爬虫自动搜索某类商品,然后获取信息,得到自己想要的结果,每天定时爬一下自己就可以决定在什么时候低价的时候买下心仪的商品了。或者说自己想收集某类信息集合成自己的数据库,但是手动复制粘贴特别的麻烦,这时候爬虫技术就可以帮上大忙了对不对?
0×01 要求
那么本系列文章旨在普及爬虫技术,当然不是那种直接拿来爬虫框架来说明的。在本系列文章中,笔者尽力从简到难,简明地介绍爬虫的各种要素,怎么样快速编写对自己有用的代码。但是对读者有一定小小的要求:看得懂python代码,然后自己能动手实践一些,除此之外,还要对html元素有一定的了解。
0×02 你能学到什么?
当然爬虫的文章在网上很容易找到,但是精致,系统地讲解的文章还是比较少,笔者在本文和今后的文章将介绍关于爬虫的各种各样的知识:
大致上,本文的写作顺序是单机爬虫到分布式爬虫,功能实现到整体设计,从微观到宏观。
1. 简单模块编写简单爬虫
2. 相对优雅的爬虫
3. 爬虫基本理论以及一般方法
4. 简单Web数据挖掘
5. 动态web爬虫(可以处理js的爬虫)
6. 爬虫的数据存储
7. 多线程与分布式爬虫设计
如果有读者想找一些爬虫的入门书籍来看,我推荐《web scraping with python》,这本书是英文版目前没有中文译本,但是网上有爱好者在翻译,有兴趣的读者可以了解一下。
0×03 知识补充
在这里的知识补充我其实是要简单介绍目前主流的几种爬虫编写用的模块:
Htmllib(sgmllib),这个模块是非常古老的一个模块,偏底层,实际就是简单解析html文档而已,不支持搜索标签,容错性也比较差,这里指的提醒的是,如果传入的html文档没有正确结束的话,这个模块是不会解析的,直到正确的数据传入或者说强行关闭。
BeautifulSoup,这个模块解析html非常专业,具有很好的容错性,可以搜索任意标签,自带编码处理方案。
Selenium,自动化web测试方案解决者,类似BeautifulSoup,但是不一样的是,selenium自带了js解释器,也就是说selenium配合浏览器可以用来做动态网页的爬取,分析,挖掘。
Scrapy框架:一个专业的爬虫框架(单机),有相对完整的解决方案。
API爬虫:这里大概都是需要付费的爬虫API,比如google,twitter的解决方案,就不在介绍。
笔者在文章中只会出现前三种方式来做爬虫编写。
0×04 最简单的开始
最开始的一个例子,我将会先介绍最简单的模块,编写最简单的单页爬虫:
Urllib这个模块我们这里用来获取一个页面的html文档,具体的使用是,
Web = urllib.urlopen(url)
Data = Web.read()
要注意的是,这是py2的写法,py3是不一样的。
Smgllib这个库是htmllib的底层,但是也可以提供一个对html文本的解析方案,具体的使用方法是:
1. 自定义一个类,继承sgmllib的SGMLParser;
2. 复写SGMLParser的方法,添加自己自定义的标签处理函数
3. 通过自定义的类的对象的.feed(data)把要解析的数据传入解析器,然后自定义的方法自动生效。
import urllib
import sgmllib
class handle_html(sgmllib.SGMLParser):
#unknown_starttag这个方法在任意的标签开始被解析时调用
#tag为标签名
#attrs表示标签的参赛
def unknown_starttag(self, tag, attrs):
print "-------"+tag+" start--------"
print attrs
#unknown_endtag这个方法在任意标签结束被解析时被调用
def unknown_endtag(self, tag):
print "-------"+tag+" end----------"
web =urllib.urlopen("http://freebuf.com/")
web_handler = handle_html()
#数据传入解析器
web_handler.feed(web.read())
短短十几行代码,最简单的单页面爬虫就完成了,以下是输出的效果。我们可以看到标签开始和结束都被标记了。然后同时打印出了每一个参数。
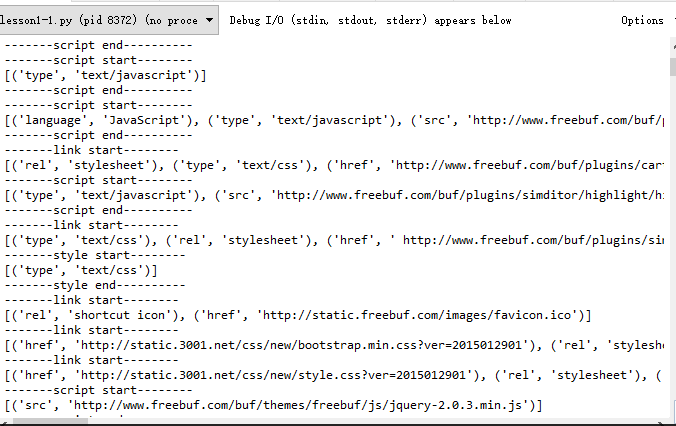
接下来我们可以使用这种底层的解析方式来做个基础的小例子:
下面这个小例子在标签开始的时候检查标签中的attrs属性,解析出所有的参数的href属性,知道的读者都知道这基本是被一个爬虫的必经之路。
import urllib
import sgmllib
class handle_html(sgmllib.SGMLParser):
defunknown_starttag(self, tag, attrs):
#这里利用try与except来避免报错。
#但是并不推荐这样做,
#对于这种小脚本虽然无伤大雅,但是在实际的项目处理中,
#这种做法存在很大的隐患
try:
for attr in attrs:
if attr[0] == "href":
printattr[0]+":"+attr[1].encode('utf-8')
except:
pass
web =urllib.urlopen("http://freebuf.com/")
web_handler = handle_html()
web_handler.feed(web.read())
解析结果为:
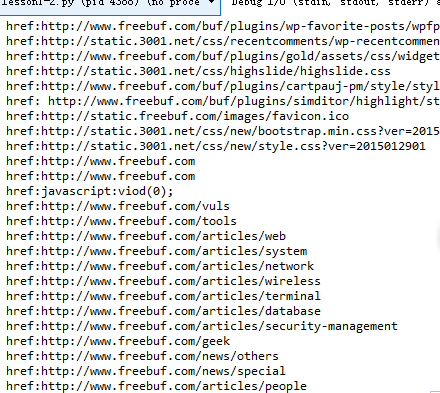
我们发现在解析出的href种,存在一些不和谐的因素,比如JavaScript的出现,比如其他域名的出现,或者有些读者说的,url有重复。实际上,这是对于我们的FreeBuf站来说,但是对于互联网上的各种复杂环境来说,上面的考虑是完全不够的。关于这一点我们稍后再做讨论。
但是笔者并不计划就用这个方法来把我们的问题处理完全。因为我们有更优雅的解决方案。
0×05 更优雅的解决方案
当然我说的时BeautifulSoup,为什么选用这个模块呢?笔者私认为这个模块解析html非常专业,这里简称bs4,读过bs4的读者都很清楚。实际上beautifulsoup并不只是简单的解析html文档,实际上里面大有玄机:五种解析器自动选择或者手动指定,每个解析器的偏重方向都不一样,有的偏重速度,有的偏重正确率。自动识别html文档的编码,并且给出非常完美的解决方案,支持css筛选,各种参数的方便使用。
BeautifulSoup的一般使用步骤:
1. 导入beatifulsoup库 :from bs4 import BeautifulSoup
2. 传入数据,建立对象: soup = BeautifulSoup(data),
3. 操作soup,完成需求解析。
下面我们来看具体的代码实例:
from bs4 import BeautifulSoup
import urllib
import re
web =urllib.urlopen("http://freebuf.com/")
soup = BeautifulSoup(web.read())
tags_a =soup.findAll(name="a",attrs={'href':re.compile("^https?://")})
for tag_a in tags_a:
printtag_a["href"]
这一段与sgmllib的第二短代码相同功能,但写起来就更加的优雅。然后还引入了正则表达式,稍微过滤下链接的表达式,过滤掉了JavaScript字样,显然看起来简炼多了:
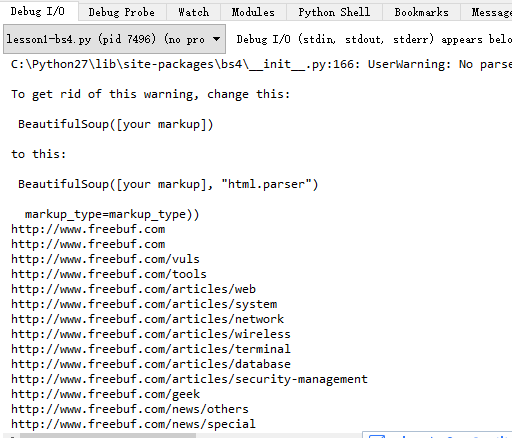
简单解释一下上面的warning:
UserWarning: No parser was explicitlyspecified, so I’m using the best available HTML parser for this system(“html.parser”). This usually isn’t a problem, but if you run thiscode on another system, or in a different virtual environment, it may use adifferent parser and behave differently.
To get rid of this warning, change this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup],”html.parser”)
上面的内容是说:没有特别指明解析器,bs4使用了它认为最好的解析器html.parser,这一般不会出问题,但是如果你在不同的环境下运行,可能解析器是不一样的。要移除这个warning可以修改你的beautifulsoup选项改成BeautifulSoup(data, “html.parser”)
这个warning表明了bs4的自动选择解析器来解析的特性。
0×06 url和合法性判断
url与uri其实是一个东西,如果但是我们更多的不提uri,那么我们来说一下关于url的处理:如果说像我们一开始那样做的话,我们手动,或者通过正则去分析每一个url,我们要考虑url的各种结构,比如下面这些例子:
path?ss=1#arch
http://freebuf.com/geek
?ss=1
path/me
javascript:void(0)
/freebuf.com/s/s/s/
sssfadea://ssss.ss
path?ss=1&s=1
ftp://freeme.com/ss/s/s
path?ss=1
#arch
//freebuf.com/s/s/s/
https://freebuf.com:443/geek?id=1#sid
//freebuf.com/s/s/s
我们大概就是要处理这么多的不同形式的url,这些都是在网页上非常有可能出现的url,那么,那么我们怎么判断这些的合法性呢?
先以//分开,左边时协议+‘:’,右边到第一个’/’是域名,域名后面时路径,?后面时参数,#后面是锚点。
这么分析来的话写代码判断应该不是一个特别困难的事情,但是我们并没有必要每次都去写代码解决这个问题啊,毕竟我们在使用python,这些事情并不需要自己来做,
其实我个人觉得这个要得益于python强大的模块:urlparser,这个模块就是把我们上面的url分析思路做了实现,用法也是pythonic:
import urlparse
url = set()
url.add('javascript:void(0)')
url.add('http://freebuf.com/geek')
url.add('https://freebuf.com:443/geek?id=1#sid')
url.add('ftp://freeme.com/ss/s/s')
url.add('sssfadea://ssss.ss')
url.add('//freebuf.com/s/s/s')
url.add('/freebuf.com/s/s/s/')
url.add('//freebuf.com/s/s/s/')
url.add('path/me')
url.add('path?ss=1')
url.add('path?ss=1&s=1')
url.add('path?ss=1#arch')
url.add('?ss=1')
url.add('#arch')
for item in url:
print item
o= urlparse.urlparse(item)
print o
print
然后执行代码,我们可以看一下具体的解析结果:
import urlparse
url = set()
url.add('javascript:void(0)')
url.add('http://freebuf.com/geek')
url.add('https://freebuf.com:443/geek?id=1#sid')
url.add('ftp://freeme.com/ss/s/s')
url.add('sssfadea://ssss.ss')
url.add('//freebuf.com/s/s/s')
url.add('/freebuf.com/s/s/s/')
url.add('//freebuf.com/s/s/s/')
url.add('path/me')
url.add('path?ss=1')
url.add('path?ss=1&s=1')
url.add('path?ss=1#arch')
url.add('?ss=1')
url.add('#arch')
for item in url:
print item
o= urlparse.urlparse(item)
print o
printpath?ss=1#arch
ParseResult(scheme='', netloc='',path='path', params='', query='ss=1', fragment='arch')
http://freebuf.com/geek
ParseResult(scheme='http',netloc='freebuf.com', path='/geek', params='', query='', fragment='')
?ss=1
ParseResult(scheme='', netloc='', path='',params='', query='ss=1', fragment='')
path/me
ParseResult(scheme='', netloc='',path='path/me', params='', query='', fragment='')
javascript:void(0)
ParseResult(scheme='javascript', netloc='',path='void(0)', params='', query='', fragment='')
/freebuf.com/s/s/s/
ParseResult(scheme='', netloc='', path='/freebuf.com/s/s/s/',params='', query='', fragment='')
sssfadea://ssss.ss
ParseResult(scheme='sssfadea',netloc='ssss.ss', path='', params='', query='', fragment='')
path?ss=1&s=1
ParseResult(scheme='', netloc='',path='path', params='', query='ss=1&s=1', fragment='')
ftp://freeme.com/ss/s/s
ParseResult(scheme='ftp',netloc='freeme.com', path='/ss/s/s', params='', query='', fragment='')
path?ss=1
ParseResult(scheme='', netloc='',path='path', params='', query='ss=1', fragment='')
#arch
ParseResult(scheme='', netloc='', path='',params='', query='', fragment='arch')
//freebuf.com/s/s/s/
ParseResult(scheme='',netloc='freebuf.com', path='/s/s/s/', params='', query='', fragment='')
https://freebuf.com:443/geek?id=1#sid
ParseResult(scheme='https',netloc='freebuf.com:443', path='/geek', params='', query='id=1',fragment='sid')
//freebuf.com/s/s/s
ParseResult(scheme='',netloc='freebuf.com', path='/s/s/s', params='', query='', fragment='')
在urlparser返回的对象中我们可以直接以索引的方式拿到每一个参数的值。那么我们这里就有索引表了:
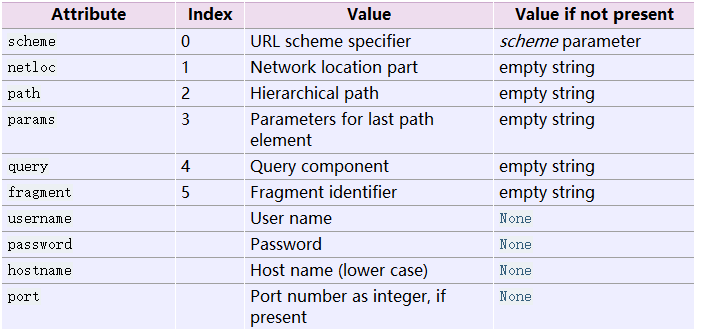
这张表的用法,
o = urlparse.urlparse(url)
o[0]表示scheme
o[1]表示netloc
……
以此类推。
我们发现:
如果scheme和netloc都同时为空的话,该url可能是当前url+path
如果scheme不为空但是netloc为空的话,该url不合法
如果scheme为空但是netloc不为空的话,不一定不合法,要具体分析,一般情况下是http
如果只存在fragment或者query的话,该url为当前的url+query[+fragment]
……
那么根据上面的规则,我们基本可以把无关的url或者不是url排除掉,或者恢复完整的url
0×07 总结与预告
本章中我们一起探究了一个简单爬虫的实现,然后稍微讨论了一下如何处理页面的url。相信读者读完本文的时候已经有了一定的对爬虫的基础认识,但是要知道,只了解到这种程度还不能说了解爬虫,这只是冰山一角。
在下一节中,我们将学到下面的知识:
1、爬虫道德与爬虫的理论知识
2、sitemap爬虫
3、简单web数据处理
*原创作者:VillanCh,本文属FreeBuf原创奖励计划文章,未经作者本人及FreeBuf许可,切勿私自转载
-
 sgmllib 在python 3.0后版本中取消了
sgmllib 在python 3.0后版本中取消了 -
太好了,正巧最近要做爬虫,谢谢作者!
-
终于知道爬虫程序是个什么东西了,之前一直不懂,以为是病毒
-
 触碰你的小妹妹不会python
触碰你的小妹妹不会python
-
 收藏
收藏
文中
知道的读者都知道这基本是被一个爬虫的必经之路。
被一个爬虫 这个是什么意思。

 关注我们 分享每日精选文章
关注我们 分享每日精选文章
不容错过
- 黑客是如何“一键”盗取汽车的?(附演示视频)饭团君2016-05-09
- Windows 10新变化:系统自动更新将“强制化”,用户不再可选dawner2015-07-20
- Bash漏洞再次演进:缓冲区溢出导致远程任意命令执行xia0k2014-09-29
- 漏洞盒子:苏宁项目榜单公布,iPhone6花落谁家FB客服2014-10-10




Copyright © 2013 WWW.FREEBUF.COM All Rights Reserved 沪ICP备13033796号
![]()
0daybank

已有 30 条评论
mark
比我写的稍好一点。
我的扫描器一直用的python读wvs的爬虫结果,感觉自己写的怎么都不如人家正儿八经公司爬虫爬的全。
@ 我是只会做题的大牛 那可能是你写的爬虫不够好啦
@ 我是只会做题的大牛 wvs只能在windows下用,不方便。我喜欢用shell调用,有啥好用的爬虫工具。不想自己写,太麻烦。
马
终于知道爬虫程序是个什么东西了,之前一直不懂,以为是病毒
不会python
收藏
文中
知道的读者都知道这基本是被一个爬虫的必经之路。
被一个爬虫 这个是什么意思。
@ amaya 翻译一下:这tm是最基础的。
太好了,正巧最近要做爬虫,谢谢作者!
小编一定是急着赶快下班去约会
python。。。
sgmllib 在python 3.0后版本中取消了
#attrs表示标签的参赛 参数写成参赛了么
多谢作者、看了收益很多
直接用scrapy框架不行吗?
@ shentouceshi 当然可以,自己写点轮子明白点过程原理,还是用成熟的框架都随意嘛
mark
不过要新学一门python
想先精通C++再说
新技能get,刚学Python不久,一直是自己造轮子,还没用过成熟的爬虫框架。
小便说的我居然听不懂
大神,请收下我的天灵盖!
用urllib2是不是也可以实现
@ 马冬梅 可以,为了图简单我直接用了urllib,推荐使用requests。
urllib2也是可以的
python新手表示不太明白0×05最後兩行代碼的意思。即
print tag_a["href"]
tag_a["href"]是什麼意思?為什麼打印它就可以得到圖裡的輸出?
@ janfytan 字典啊~~
这是什么编辑器啊?
瞧一瞧 爬虫。。


挺好的。(= =错别字瞩目。。